Kyle Samani:
Guy Itzhaki, this one’s for you. Can you introduce yourself, please? You’ve been working on the Web3 side of things for a while at Intel. What was the most interesting thing for you from those days? And what motivated you to switch over to Web3?
Guy Itzhaki:
Perfect, thanks. Yeah, a little bit of background about myself. I’ve been working for Intel for many years with various projects. I think somewhere around 2017 was when I first got introduced into the blockchain space. Back then I led Intel’s confidential compute ecosystem development, building, and leading projects through an evolving trusted execution environment. One of the first projects I did back then was actually to develop a permission blockchain network for a stock exchange for lending securities. And that’s how I got connected into the entire blockchain space. Back then, I was invited to join many conferences. I was participating there. In one of them I actually met Guy Zyskind, my partner in crime here. And we started chatting about some of the problems that we see in blockchain and the lack of data confidentiality, which eventually led to me joining Fhenix now. And then, last year, I decided that I want to transition from confidential computing and explore further the domain of homomorphic encryption, and let Intel’s homomorphic encryption business development. And we’ll talk more about FHE. And why we think it’s now the right time for homomorphic encryption, and just recently left Intel and joined Fhenix as the CEO.
Kyle Samani:
Awesome. And now Guy Zyskind. We will turn it over to you. Could you please introduce yourself? You’ve been researching and working on Web3 and privacy and confidentiality technologies for the last decade. Can you share some of your OG insights?
Guy Zyskind:
Yeah, of course. Thanks, Kyle. Yeah, I’ve been in this space longer than many people I guess. I have been here for a decade, some consider this as a badge of achievement or the other way to say that I’ve seen too many battles and barely survived to the middle. So either way, you want to look into this fine. I’ve mostly been on the, let’s say, privacy encryption side of things on blockchain, like I’ve been basically the guy with the sign ever since like 2014 saying, “Look, unless we solve privacy. And unless we solve like encryption, then, this whole Web3 thing can actually go so far.” So I still think that message is surprisingly valid a decade later. We’ll probably get a little bit more about it like what were the twists and turns. For those who don’t know, like I actually wrote, like, probably the first two papers to actually describe this whole problem of confidential smart contracts. This was back in like 2015. And then I went ahead and kind of spun that out into a project that became secret network, which kind of spearheaded in production, this idea of private smart contracts. And obviously now continuing data, mostly on research and product side with Fhenix, and FHE. And clearly kind of like, I’d say, at least for me, in my own personal journey is because I think we were waiting for FHE all along, it just wasn’t there yet. But it much like [ZK] wasn’t there yet until like 2015 in the beginning, and so I kind of feel that, like we’re having the same transition right now with FHE. Maybe just like a couple of like, “[Unclear 00:16:53] sites, at least, like in retrospect, two things that I find a bit surprising is that, if I’m thinking about like the early, like, 2014, 13, 14 15 cohorts, like, we all thought that like a decade later, it’s either going to be the case that crypto is like bust, like it’s dead, like, no one’s going to care about it, it’s not going to be useful, or there’s going to be these like explosion and widespread mainstream adoption, it’s going to be everywhere. And I think that we are somewhere in between. Everyone knows about crypto, but it’s still the case that it’s like not mainstream adopted, which is I don’t think any one of us from the early days actually expected that to be the case or a possible outcome. And I think the other interesting part is, if you think about those days, and you extrapolate it today, you see that most of the, let’s say, things that caught on in crypto, they had like the fairest versions or thoughts or ideas, even as far as a decade ago. So no one knew that DeFi would ever be a thing. No one thought about DeFi, the term didn’t exist. But even in 2013-14, people were trying to build decentralized exchanges, which was like one of the first projects I tried to do. No one knew how to solve scalability yet, but everyone knew that’s a problem. And everyone knew that it’s probably going to take one or two directions, either gonna be like off chain layer-2 scalability. And again, layer-2 wasn’t the thing, but people call it like off-chain computing. And that obviously turned into a big thing with rollups. But that was not known back then. Or the other version is that people knew that you’re going to have to find a more scalable layer-1, which I’d say is like another direction that other projects have successfully taken like Solana and others. So to me that’s also a surprising insight, like even 10 years back, people kind of identify the problem and a first approximation of the solution. And then, today, we’re actually seeing how that has manifested sense.
Kyle Samani:
Already, and now next up, Tarun, could you please introduce yourself? Could you share your initial impressions and understanding about the chief technology and how it relates to blockchain?
Tarun Chitra:
Yeah. Hey, So I am Tarun, Founder of Gauntlet and also an investor in Ever Above ventures. I think my experience sort of, actually goes back more to 2011 or 2010. I was like about to graduate college and I was like, “Oh, should I really do this PhD in physics that I got accepted to or not?” And around the time I started reading Craig Gentry, his PhD thesis, which came out around then. And Craig Gentry is sort of this kind of crazy guy who was the first to figure out how to make FHE actually work in his PhD thesis. And at that time, it just felt like this kind of very magical thing. But it also seemed a little bit crazy, because the objects, the mathematical objects you needed to deal with were just very unruly, I couldn’t imagine someone actually figuring out how they implemented it. But it just had this very nice, elegant feel of, “Hey, I can do all these operations completely privately, and separate sort of the execution of something from the privacy of the inputs and the privacy of the entire execution trace.” So I’ve always kind of, in the back of my head, had that as the thing that inspired me way before, the outside sort of blockchains and DeFi stuff. But I think what has kind of over the last couple years, been, the reason for that this captivated me, is that there’s a lot of mechanisms within Defi, that, basically can’t be made private, alone with ZK, you can get some forms of privacy for those applications, but you can’t sort of completely make them private. So the simplest example is an AMM. AMM always has to have a public price. But from the public prices, you can kind of reverse engineer what trades cause those price changes because you know exactly the sort of deterministic way the AMM function has to change. And so, no matter what you do, even if I ZK the reserves of the AMM or I ZK certain states that users have, I’m still not really actually preventing people from figuring out what the trade sizes and front running are doing different types of actions with that form. The second thing is things like MEV, you could view them as sort of, really arising from this tradeoff between utility and privacy, where the more information you reveal, the potentially better execution you get. But at the same time, it also, you have kind of some of these adverse effects. And when you start thinking about how to design MEV auctions, things like suave, things of that form, where you have the split between private state and public state, you inevitably come to run into some of the limitations of just ZK alone. And so that sort of the lens, I view this from.
Kyle Samani:
All right. Now next, we’re gonna get back to Guy Itzhaki for a handful questions. Guy Itzhaki, could you please explain what is FHE? Someone who knows very little about FHE?
Guy Itzhaki:
Yeah, for sure. So I think in the most simple way to describe FHE, which I will say is a very novel encryption technology that’s existed for several years, is an ability to run computation and data while the data is encrypted. And if we take a step back and actually think about it, prior to FHE, when we encrypted data, we couldn’t really do anything with this data, if we wanted to do anything. We basically had to decrypt it, whether we decrypt it in a trusted executed issue environment or outside of it, and then we ran the computation on top of that. The normal thing about FHE is that now we don’t necessarily need to encrypt the data in order to run whatever computation we run on top of it. But rather, we can actually do the computation on the data while it’s encrypted. And that opens a whole new set of applications around that specifically in the blockchain space. We’re all familiar with the challenge that we’re facing today in the blockchain world that the data is transparent for everybody to see. And that’s actually one of the reasons that we’ve decided to start Fhenix is the ability to finally provide a way to do operations on data while it’s encrypted, and in that way, meaning that we can have data on chain, still encrypted, but still do us use cases that I’m gonna talk about later on.
Kyle Samani:
Okay, awesome. And then the next question is what is going to make FHE implementation and Web3 so exciting.
Guy Itzhaki:
Okay, maybe Guy Zyskind can take this one and I’ll answer in a minute.
Guy Zyskind:
I don’t know, this is like an open-end question. But I guess, there are several ways to look at this. If I’m putting the research ahead, then like, until Bitcoin people were trying in cryptography and distributed systems to kind of build this one machine or distributed system that solves eCash, like the ability to cryptographically send transactions from one to another without double spend and all that. And that was like a huge thing, when Bitcoin came because it kind of solved what cryptographers have been talking about since like the 80s and the 90s. And I feel that, cryptographers have been talking about this world, where there’s like, these trusted, if you really like a world computer on the cloud, like this trusted computer on the cloud, that allows everyone to basically, run whatever logic or functions or code or application that they want, but they can trust it to hold their data securely, not leak it. And then, run those computations faithfully. This is basically called Secure Computation, literally, it describes what it is, and blockchains, with smart contracts kind of got us halfway there. We trust the blockchain not to cheat because it can’t, unless it’s broken in some really bad way. But we don’t trust it to keep our data private or encrypted or secure. And that is basically what kind of like FHE complements. And I think having that kind of system having that kind of power outside in the world, if we can make it happen, that very smart people have been trying to conceptualize for, like 40 years now, is very exciting.
Guy Itzhaki:
And maybe just adding to that, I think one of the biggest promises of blockchain was that it enabled users to own their data, but not really to control who they share their data with. And I think the addition of FHE into that space is that now for the first time, we’re actually enabling users to control who can see their data, who they share their data with, and potentially even monetize that, which I think is one of the more exciting parts of that.
Kyle Samani:
Okay, and then next question for I guess, Guy Itzhaki or Guy Zyskind, whoever can take it, but why is now the right moment for Fhenix to launch?
Guy Itzhaki:
I think everybody mentioned it already. But FHE has been discussed for many years. But up until now, it was quite hard to implement. It’s computation bound. It’s very complex. But there’s been several advancements in that space, both in terms of computation. And in terms of simplifying the complexity. If you ask people who are involved in the FHE space for many years, they’ll say, “Yeah, in theory, we can do FHE. But trying to run it on a large amount of data, it would just not be feasible.” But what we’ve noticed then, was that by actually running FHE computation on right hardware plus improvements that’s happened in the FHE algorithms themselves, made it quite feasible for deployment today. And a lot of the complexities that we’re considering in the past or obstructed by the right usage of compilers and libraries, that absorbs the complexity. And when we decided to start Fhenix, one of the key goals for us was to make it as easy as possible for developers to develop, they don’t need to learn a new language, or they don’t need to become experts in FHE. And once that was able to be done, it was quite obvious that is a great time to start Fhenix, since we have a known problem in that space, right? The lack of data confidentiality, plus we have the right cryptographic solution here that can bring the solution. So I think it’s quite exciting because we’re literally seeing the hockey stick coming up in the next, I would say 12 to 18 months, with the introduction of dedicated hardware for FHE which would speed up performance even further standardization bodies that are working on FHE will be released in 2025. As well as a shift in how the blockchain community starts treating data confidentiality.
Guy Zyskind:
Also, this is like a great place to mention Zama. We’re working with Zama very closely on these Zama has been at the forefront of FHE from the last few years. They have like some of the most brilliant minds, and engineers working on making FHE much faster. And, just working with them to get on the journey. It’s pretty clear, at least to me, and hopefully to others that like this is like Guy Itzhaki was saying, we’re experiencing this hockey stick moment, in the sense like, I feel this is very similar to what we saw with ZK technologies, like 2015, people were like, “Yeah, maybe it’s okay for payments, but it’s not gonna scale for anything else.” Then 2017, people started to pay attention. And then it just like hit critical mass, and the rest of the story. So it does seem that there’s a lot of similarities, at least when it comes to how fast like FHE is going to scale now similar to what we saw with the ZK.
Guy Itzhaki:
And it’s probably worth mentioning that one of the more exciting things about FHE is that, yeah, we’re starting the journey, and the blockchain space. But the potential of FHE goes way beyond the blockchain world. We see the interest in Cloud service providers, financial institute’s which will eventually drive significant investment and resources, education and hardware. And definitely, since we’ve announced Fhenix and the work that we’ve done with Zama, we saw a spike in the interest and FHE, that’s a good sign. And we definitely believe that the next two years are going to be quite phenomenal in terms of the market education and market need for data confidentiality.
Kyle Samani:
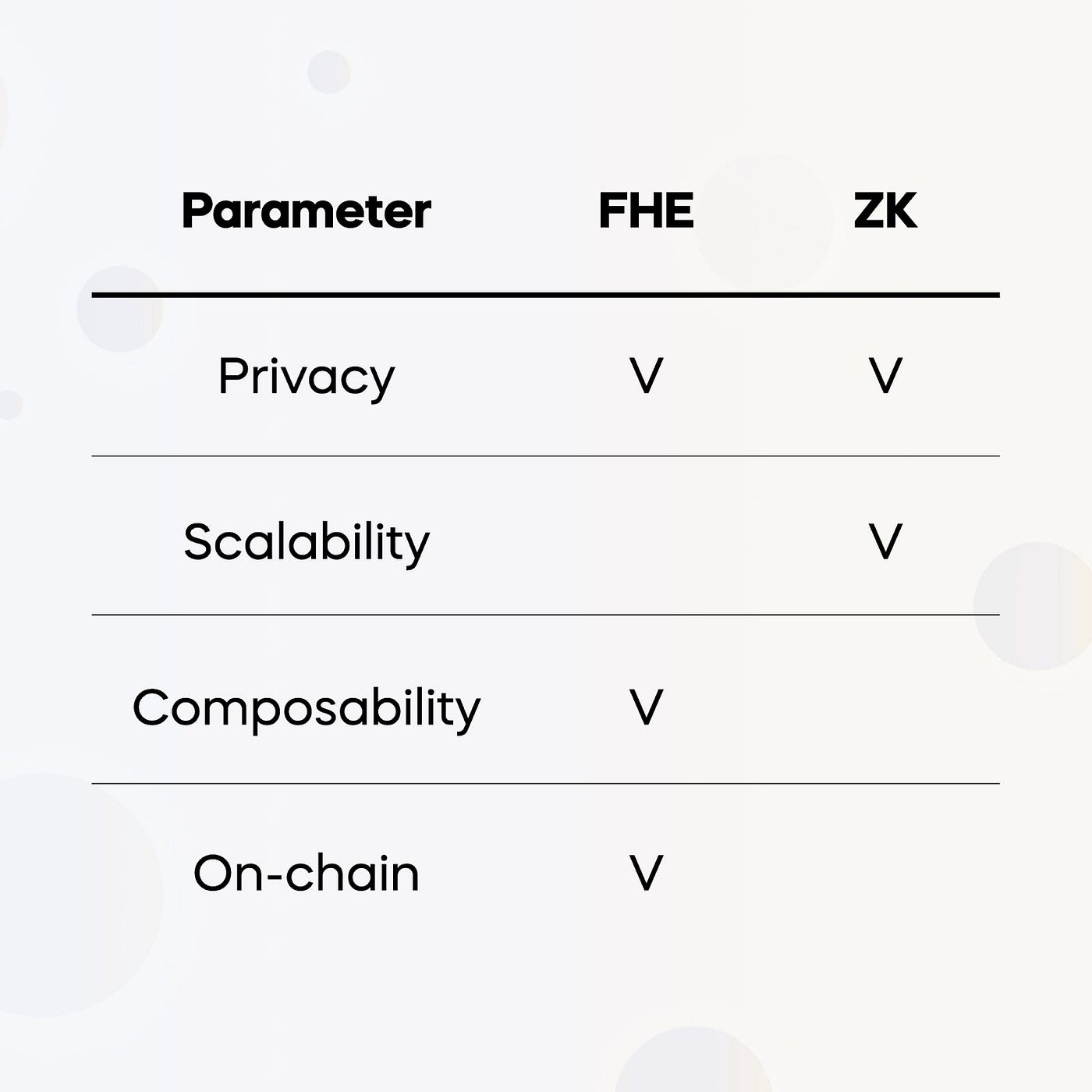
All right. Next up, guys, I think we have FHE different from zero-knowledge cryptography such as STARKs?
Guy Zyskind:
Yeah, that’s a very good question. Because, I feel that’s like a pretty big misconception. Although people are starting to kind of pick up and understand the differences. I think the best way is to just give maybe a couple of examples and kind of like frame FHE and ZK in each of those. So, FHE, first of all, FHE is, people said before, basically allows you to compute over encrypted data without decrypting it. So again, like given maybe an example or to imagine like, Kyle, Tarun, myself and Itzhaki, we want, for example, compute, which one of us earns the most money, like, who gets the highest salary, but we don’t want to share our own salaries with each other, we just want to get a result, like, who is that person, this is basically computing the max function between the four of us. So I mean, with FHE, it’s conceptually, trivially forever FHE, like each one of us can encrypt the data using the same key, then each one of us, we can sell it to some Cloud server out there that understand, that can run FHE computations, can basically take all of our encrypted inputs, and basically compute the max function of them and just send them the result. And if you try to do that with ZK, for example, this is impossible. ZK doesn’t work that way. In ZK, there’s a prover and there’s a verifier. The prover, basically, is the one doing the computation. So, basically the prover has some data, it can run some computation of the data. And then it can send someone else that someone could be like, anyone, the result and say, “Here’s the pool that I actually computed over the data that I have, but I’m not going to show you the correct result. And here is the result. And here is the proof that it was done correctly.” So if we take the same example, where we want to compare all of our salaries, now we have this single point of trust that we just can’t avoid. So maybe we trust or maybe we settle Kyle on trusting you, meaning each one of us is sending you our salary. And then you compute the max, like, who earns the most money. And then you send a proof, a ZK proof to everyone. You don’t reveal the underlying salaries, although you solve them. But you do tell everyone else with the proof who is earning the most money. Another similar example of this, maybe, let’s say, for example, is using something like an encrypted ChatGPT. So I think I speak for everyone, when I say that sometimes, you ask ChatGPT some questions that you might not actually feel that comfortable sharing, especially if there’s some business secrets, or some very private information about yourself. Now, imagine that all of this was done in FHE. So you could theoretically have a solution where you encrypt your prompts to ChatGPT. And then ChatGPT basically runs the same thing it does today, but over the encrypted data, and then sends you back the result without actually ever decrypting or seeing your own query. Again, that is possible with FHE. But that’s not something you could do with ZK, like, the best you can do with ZK, for example, is you can send a ChatGPT your query, your prompt in the clear, and it will see a query. So, [no better than], but it can at least maybe verify to you like to prove to you that it actually ran the latest model, and it didn’t run ChatGPT 3 instead of 4, for example. So the bottom line is like the two actually solve different problems. They’re useful in different contexts. But if you really want to combine data from different people, that’s private, if you really want to be able to just get a level of privacy, like ZK only gets you so far, and FHE actually gets you all the way.
Kyle Samani:
All right. Next up, we are gonna get to Guy Zyskind, what is your vision for Fhenix and FHE and Web3?
Guy Zyskind:
Yeah, so this can be much shorter, we kind of touched on that. Like I said, I’ve been the guy with the sign for 10 years saying that, like we have to solve problems like on-chain, like lack of confidentiality, lack of privacy, not just because people care about the data, that is obviously a very important thing. But because of how Web3 works. In Web3, everything is published, which means that there’s just a lot of use cases that you simply cannot do without FHE. So you want to do private voting, you need something like FHE. Again, there are other solutions, but that’s probably like the Daisy Swan, you want to do MEV Auctions, as Tarun mentioned, you need something like FHE. You want to do an on-chain game. You want to do a simple game of [on-chain] poker, you can’t actually do that with ZK, you can do it on a blockchain because everyone is going to see your cards, and then there’s no game. So you need to FHE. So there’s clearly a world of applications that you just cannot do unless you have on-chain FHE. And to me, that’s like what’s exciting and that’s really the vision. The vision is that five years from now, using Fhenix, using FHE like people will realize in retrospect that there were so many applications that they could not have done today without FHE being available to them.
Guy Itzhaki:
And maybe just adding on top of that clearly Guy Zyskind gives examples of where a Fhenix and if he can bring value to existing Web3 applications today. My background is, I’ve been in the corporate space for many years. I have no doubt that if we want to make blockchain a success and actually have it widely used, and have corporations and financial Institute’s start seeing Web3 as the future. You have to have data confidentiality. There is no way that financial institute’s will put anything financial if they know that others can see it. So yeah, it’s a longer term and it will take time, but for me, transparency is a feature in some applications, but it’s definitely a blocker to many of the use cases that Zyskind described. But the ones that we’re actually haven’t even started thinking about.
Kyle Samani:
All right, next up. Guy Zyskind, can you tell us about your recent research and findings in FHE, and the rollups and the white paper you all just published for Fhenix?
Guy Zyskind:
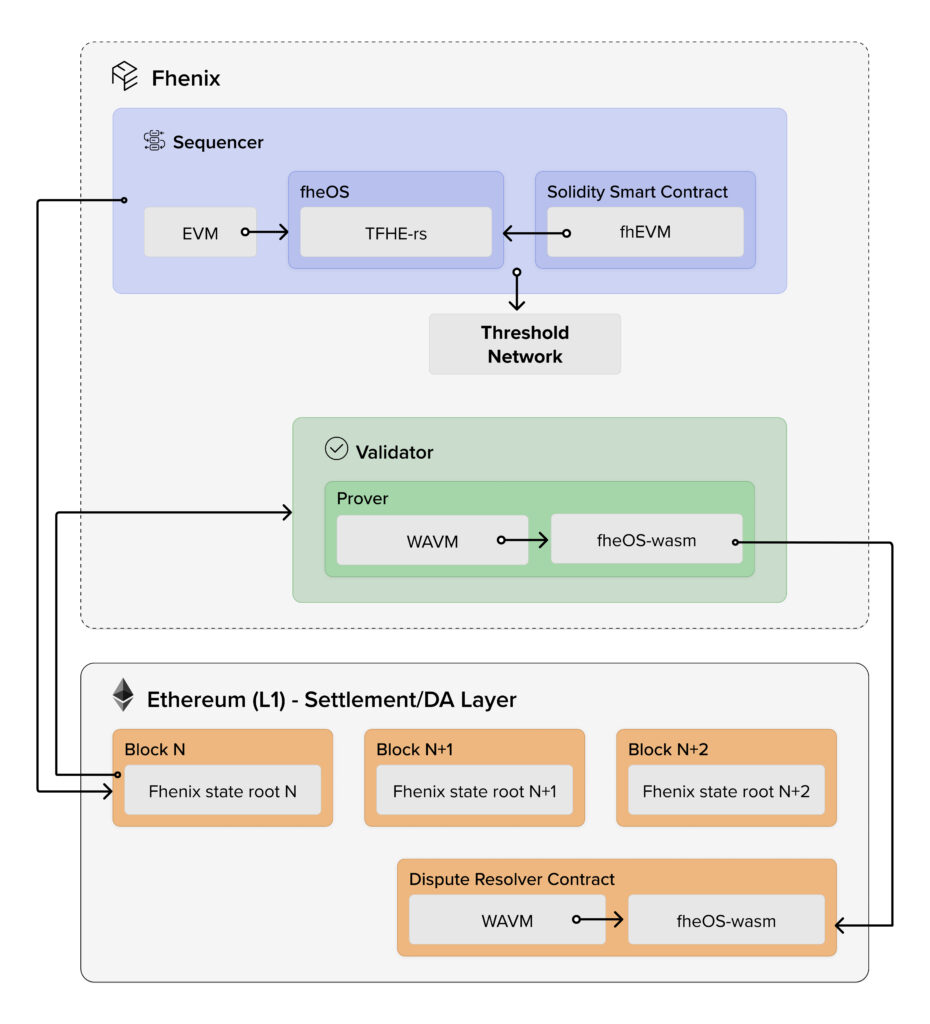
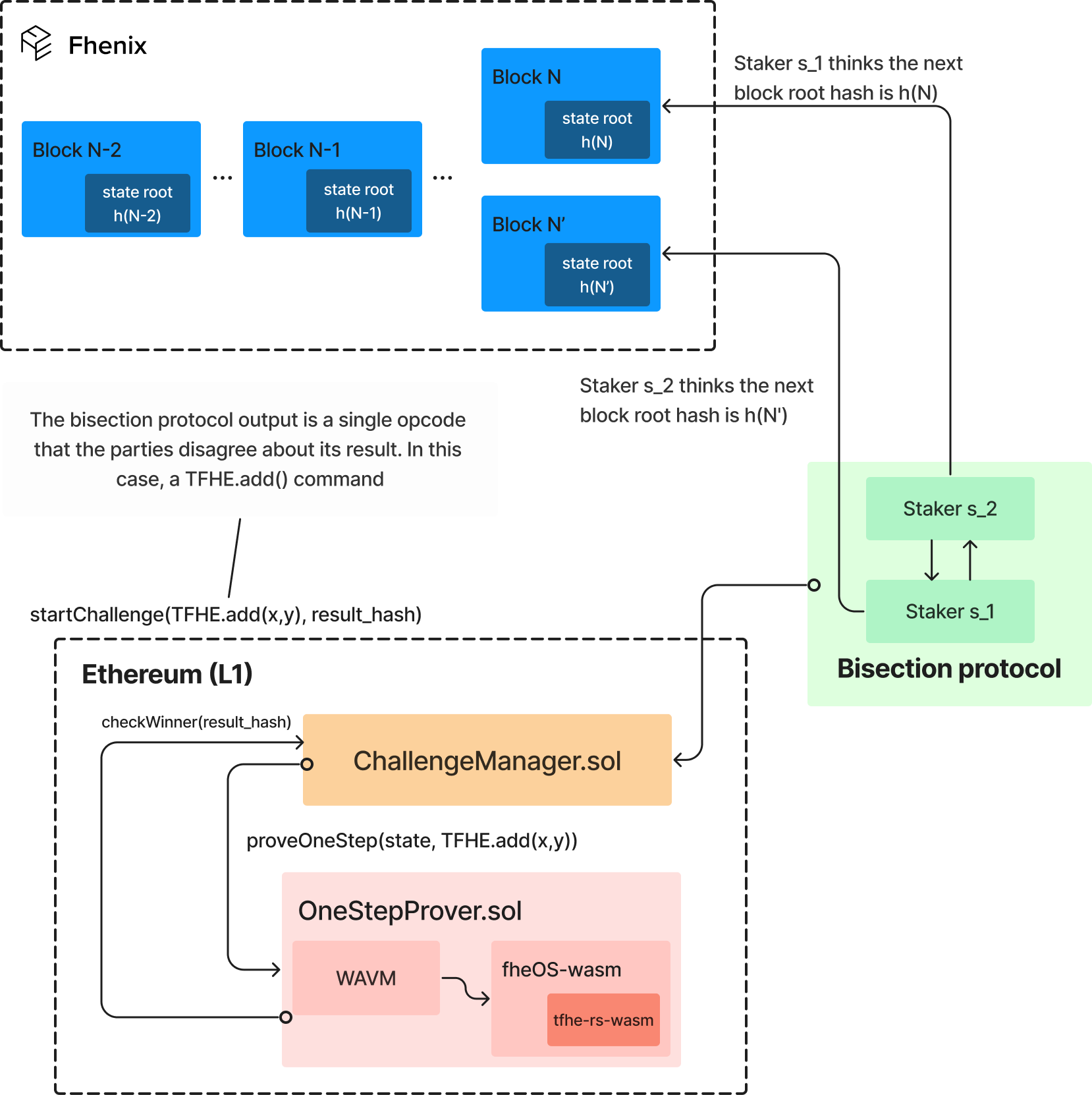
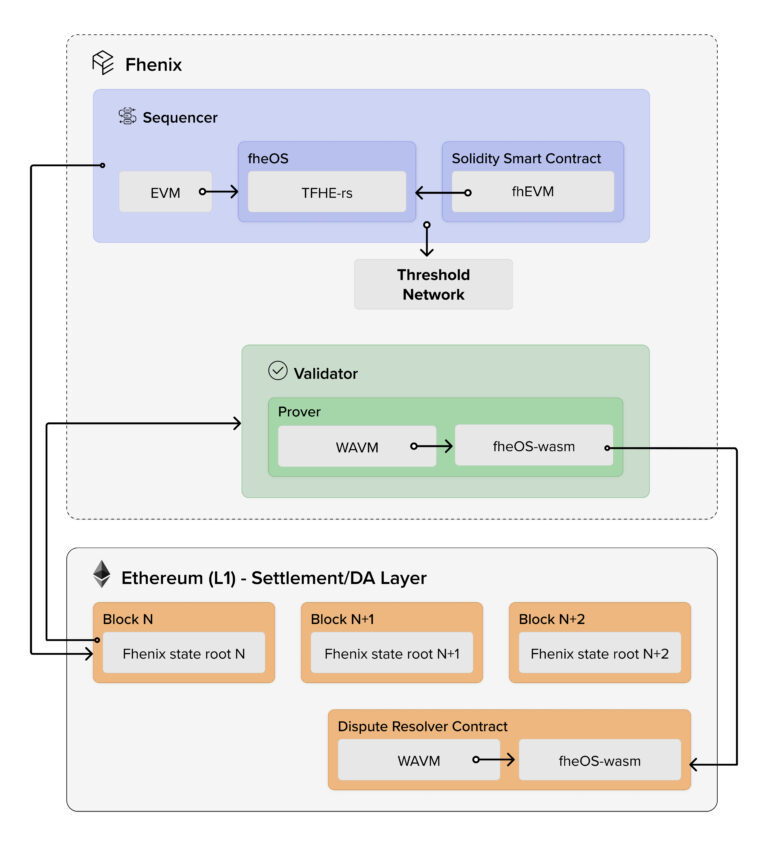
Of course, and obviously, we can go as deep or shallow as we want. But just at a very high level. I think first of all, the white paper basically makes two observations. One observation is that, although the technologies are very similar, ZK and FHE, they share a similarity where both ZK and FHE, they require very heavy to do cryptography, which means that there’s no going around it, like whoever runs computations with FHE, is probably gonna have to run like either very expensive servers, or gonna have to utilize like, specialized hardware. Again, we’re seeing the same thing with ZK provers so that’s the similarity there. And that kind of bottleneck, let’s say, is a much better fit for a rollup architecture, where not all validators basically replicate the computation on the first layer, and duplicate it, and then you have like an x50, x100, x1000 depends on the number of nodes, cost factor for each computation. Plus, you have to wait until kind of like, the weakest link, the slowest node in that. So FHE, if you feel that you need rollups, when you’re not using FHE, where you are using it on plaintext, you definitely want FHE to be running in the world of architecture. That’s observation number one. Observation number two, and that’s a bit more nuanced. So hopefully, at least some of it will be clear to others. But it’s not that bad. The fact that FHE is, unlike other privacy technologies, like secure multi-party computation, when you’re doing FHE, you’re basically just working with encrypted beats, with like cipher texts. And everyone can see the cipher text, like you can publish them on-chain, is the whole on, like, you can publish the actual encrypted transactions on-chain, you can send it around, you don’t need to be selective in what you share with other parties. So again, it’s very, very amenable, it’s very constructive for a rollup architecture. Compare that with, again, sometimes secure multi-party computation, where you kind of have different validators and each validator, you have to share some different version of the encrypted data. And you can’t actually make the public because then you actually repeat the data. So those were the two observations why it’s needed and why it can work. The biggest open question that we had was, how do we do it? So you can actually do a ZK on top of FHE all up? But that is very expensive. Like the latest research says, this is three folders of magnitude slower. There’s a lot of people working on advancing it, including Zama, including [Unclear 00:43:45], we’re talking to, but it’s not there yet. That’s gonna take a while. So then the other question was, okay, on the optimistic avenue, the optimistic FHE rollup avenue, can that be done? And there the problem was, we want to build this on top of Ethereum. But then how do you actually do settlement of transactions or smart contract executions that are under the hood not running, like playing solidity. Well, solidity, but they’re not running, playing EVM under the hood, they’re actually running some pretty sophisticated technology. And we solve that, like we actually had to work for a few months to actually make sure that we solved that and we worked very closely with the [Unclear 00:44:35] team, who wrote the general purpose Web Assembly prover that works on the Ethereum L-1, which plugged beautifully into what we’re doing. But I think that’s the biggest breakthrough, like the fact that you can actually build an FHE rollup on top of Ethereum L-1 today, and you don’t actually have to make any changes, or any hacks to get it to work on Ethereum. You don’t need some special EIP, an opcode to actually make them for Ethereum that it seems.
Kyle Samani:
Alright, and then just kind of following up on that. How did the FHE rollups actually work? What are the key components here? What are the other kinds of major pieces here?
Guy Zyskind:
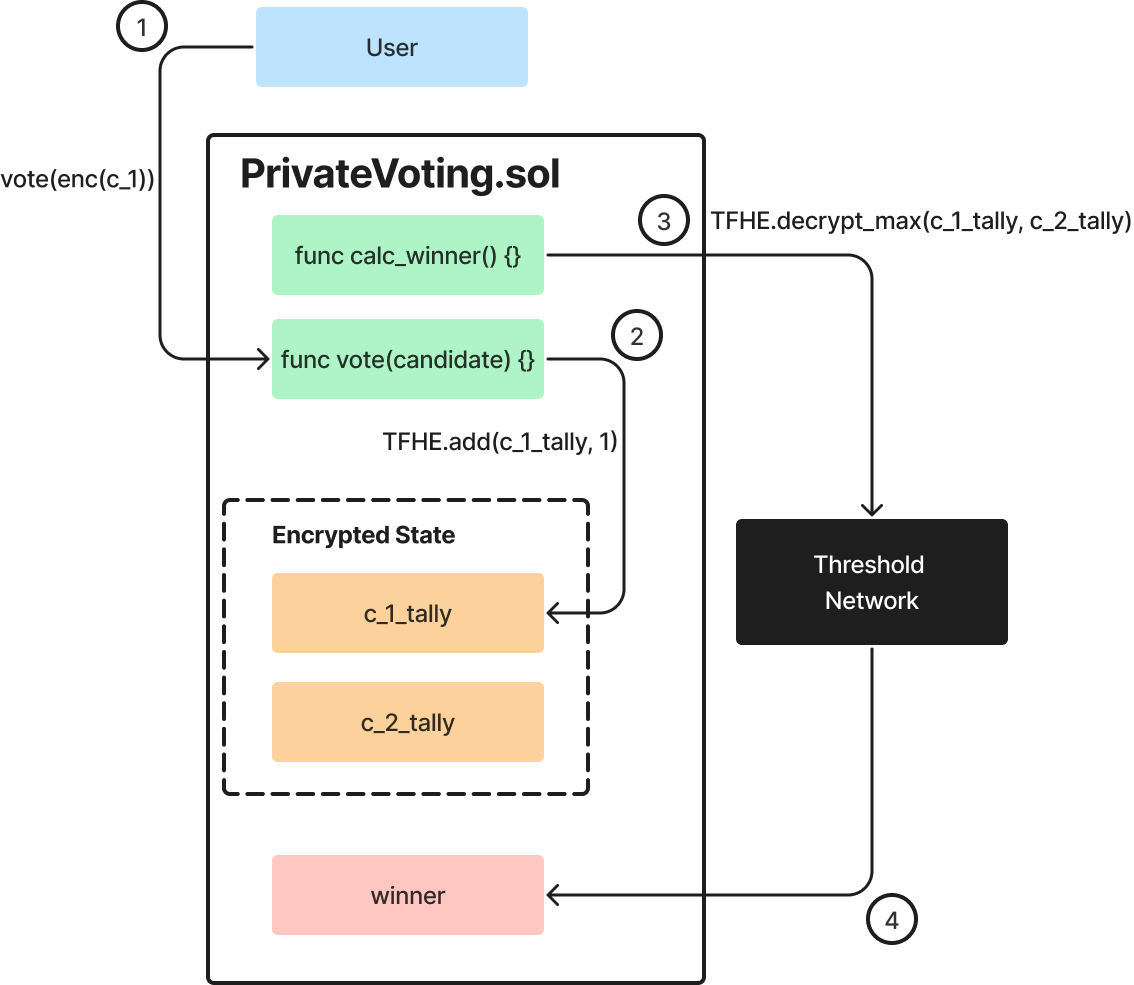
Yeah, all of the pieces are the same for the most part, they work differently to an extent, but they are generally the same, we have a sequence cell, who orders the transactions, again, transactions can be encrypted, then you have like an execution node that is actually executing those transactions, those are smart contract executions. And that has to be a pretty beefy computer, like ZK prover, this has to be something beefy that runs FHE computations. And then you have a settlement layer, which can be the Ethereum L-1. But it can obviously be other blockchains as well. And you have a data availability layer, which again, can be the Ethereum L-1, or it could be some other solution, like IDTA or Celestial, or maybe something that we cook up, there is there is a caveat here, cipher text ever blow up, they’re bigger, it takes more storage and we’ll actively working on improving that. But that is something to consider. And then the one piece that is definitely unique and different, and doesn’t actually exist in other places, is a threshold network. So without getting into too many details, whenever you read encryption, you should imagine there is a secret key somewhere. And where does that end? Who holds that secret key? In this case, we want all users to be able to encrypt via the same key or maybe there’s different keys, but at least more than one user should be able to [Unclear 00:47:06] using a single public key. So where does the secret key live? Well, that secret key lives in some treasure network. Ideally, over time, that can be something that we scale out, but probably we’ll start with something that’s fairly small. And that network is needed. Because just to give you an example, imagine you have a contract that is like a [Unclear 00:47:26] voting contract, where people basically vote on whatever outcome, we want the votes themselves to be encrypted. You can use FHE to tally the votes without decrypting or revealing anything. But at the end, do you want to be able to publicly decrypt? Like who won? Which option one or who won the election? So you need to be selected with that. And for that, you need to use the secret key in some form. So that network actually does threshold decryption, to publish the result.
Guy Itzhaki:
And, just listening to that, people should understand that even though it was a core underlying infrastructure is FHE based, the long term solution will require us to build a platform that uses ZK, for proving on the user side. FHE, for encryption, and MPC for the threshold network. So it’s not one versus the other in terms of encryption capabilities, but rather, it’s actually a combination of all three to really fulfill what’s needed here.
Kyle Samani:
All right. Next question. What makes FHE rollup such a big deal for our space? And especially for Ethereum?
Guy Itzhaki:
Tarun, do you want to take this one?
Tarun Chitra:
Yeah, for sure. So I think, if you look at the Ethereum roadmap, a lot of it is definitely focused on increasing proving capacity and increasing points where there’s aggregations of information. And that can be verified by anyone kind of relatively cheaply. I think a fundamental tenet of the Ethereum community is that nodes are relatively easy for people to run that kind of inherent belief and kind of in a lot of ways, the only ways to do that are via advanced cryptography. So that’s sort of like the highest level philosophical view of this. I think, a place that one should think of, FHE at least in my mind, when I think of threshold FHE is, you have on one hand, something like MPC where you can really– That’s used in a lot of places. It’s used in wallets, used in fire blocks, and used in Coinbase. But MPC has this problem of tons of rounds of communication, as Itzhaki mentioned earlier. On the other hand, you have ZK, which, via a lot of tricks and a lot of things that kind of people invented from 2012 to 2016, you kind of have this distinctiveness aspect. And you can kind of do things in a single step non-interactively. I think FHE sort of is in the middle in a lot of ways, there’s more communication, in some ways than the ZK. But for that extra communication, you get a lot of units of better mechanism design. So, when you think about a lot of mechanisms, say MEV auctions, people submit their transactions, the MEV searchers kind of aggregate transactions and try to figure out how to add in, either front running transactions or arbitrage transactions, then they submit that to block builders, who then kind of give the right to the proposer who wins a block in current Ethereum. In that entire sequence of that chain of events. At every step, once the user discloses their transaction, that’s completely public to everyone in that entire chain of third parties. And in a lot of ways, that’s where most of this extracted value that is not necessarily good for the end user gets lost. Now, there’s obviously efficiency that comes from people being able to see order flow, and figure out where to send it. But FHE provides, in my mind, one of, the most foolproof way of trying to make the vision of not having that value, as high as it is now, be able to reach its full potential. So if you think about the direction people are going with MEV options on Ethereum, a lot of things are looking at things like STX and that’s purely from the perspective of it being practical. But from a sort of threat model standpoint, STX is sort of one of these sorts of things where, A, it has historically had an insane number of attacks against it. B, at the end of the day, you’re still trusting Intel with the key, which is different from trusting this network of [structural] designers. And I think what we’re going to end up seeing is that STX does provide this kind of lower net value extraction for the network while keeping throughput up and keeping usability up. But people at some point, will realize the kind of end state that is a lot more, is kind of at the level of security that the room desires is going to end up having to look more like FHE and less like ZK. So maybe that was kind of a long winded answer to this. But I think within a lot of places within how transactions are processed, Ethereum improved privacy with better user outcomes for non-validator users.
Kyle Samani:
Alright, next question we’ve got here. What are one of the most interesting use cases that FHE rollups can support? Anyone can jump in here.
Guy Zyskind:
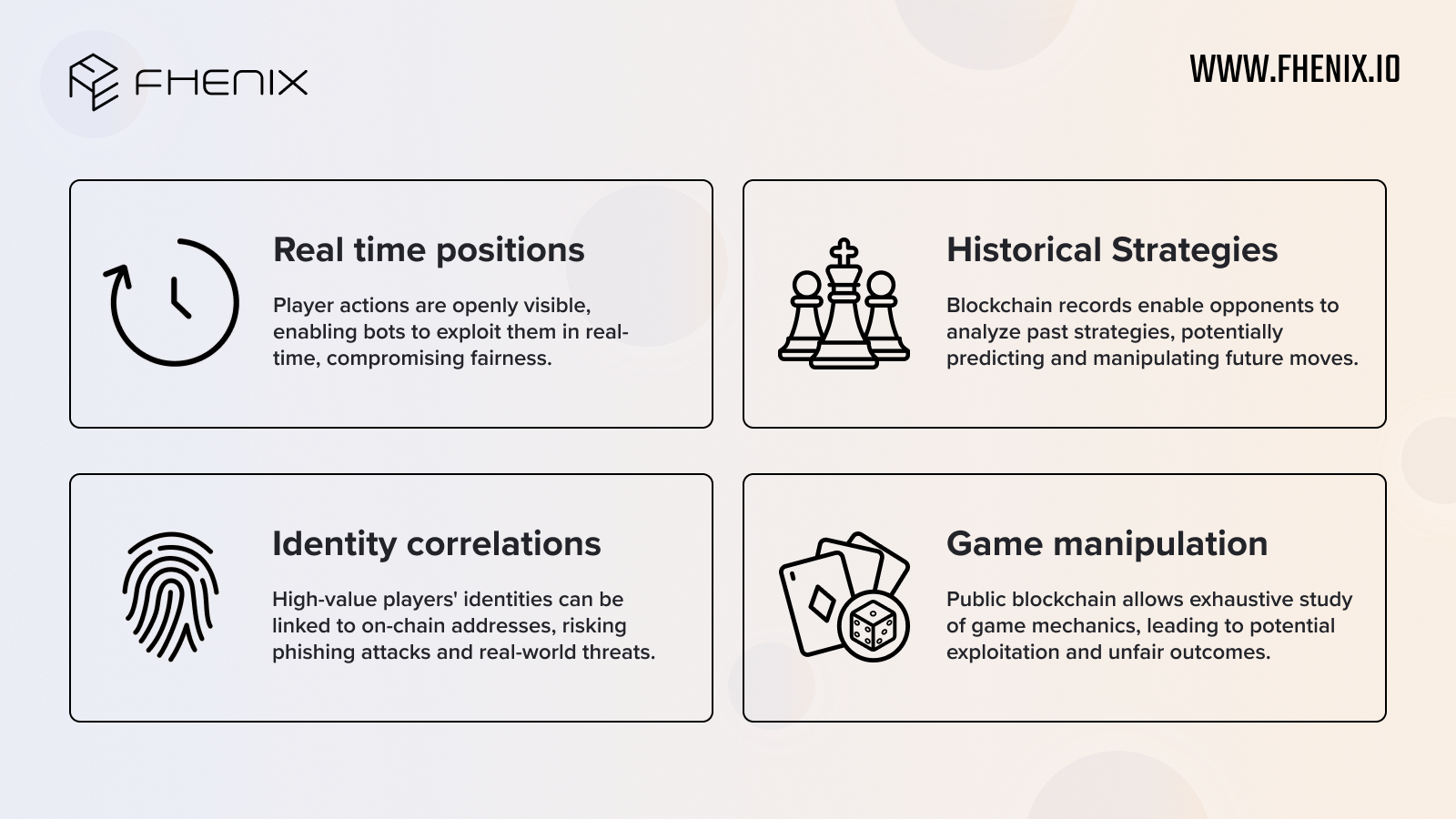
I actually agree that MEV auctions are a big thing. I’m kind of curious what other interesting mechanisms like that we can do. Like, I think we’re only scratching the surface and I completely agree with Tarun. One thing and it’s not that flashed out. But one thing that I’m pretty excited about is and I think that’s a combination of what FHE can do and simplicity and the fact that it’s, at the end of the day, developers just write like solidity contracts, is like you can build something like native BTC like native Bitcoin, native Solana, native other assets, [Unclear 00:54:58] of a smart contract Ethereum, and then you can build something like, like cross chains swap between assets without actually wrapping them first and all that, you can do something like a fully on Ethereum, very simple kind of like version like uniswap. But they actually operate cross-chain like THORChain or THORSwap. So that’s something exciting. I actually think there’s a place– That’s not necessarily a very popular thing. Or at least that creates like a lot of– There’s a lot of, let’s say disagreement in our space between like, what you can approach. But I think that you can do things like private and compliant devices or both private, but you can actually add a lot more safety features and compliance related features, just because of the level of programmability that something like FHE gives you compared to something like, private transactions using ZK. And finally, I mentioned that I think on-chain games are also very interesting. I don’t know if the market is ready for it yet or not. Maybe it is, maybe it’s not. But generally speaking, I think that on-chain game is basically dead on arrival, without FHE.
Tarun Chitra:
One thing I would add, at least just from the perspective of like, trying to write programs, is, while I think there’s a lot of, obviously, given the increase in ZK proven capacity, and the improvement in tools, I think SERCOM looks 100 times better than it did even a year and a half ago. There’s kind of this inherent overhead on developers when writing with ZK code where you have to keep track of a lot of the state that you’re using. And it’s not as clear to the end user, like which pieces of state in their program need to actually be completely private, which pieces need to be put into STARK, which parts of the circuit have to read, there’s a lot of sort of design decisions that one has to make in ZK, that I think, add a lot of overhead and complexity to the developer experience. One thing that I think I’m personally most hopeful for FHE is it actually makes it so that I might be a junior developer, who probably doesn’t know anything about how cryptography works. But I could write an application without having to have this insane overhead of like, really understanding every piece of the circuit to know where the privacy guarantees are, and, this is not necessarily a flaw in decay, and then FHE will have some of this overhead too. But it’s just that I think, if you want to have this kind of dream future where I can write F of X, and F of X does all the encryption without me having to be like, “Okay, X needs to be partitioned into secret state and public state, I need to map X to this particular representation of F,” which is the circuit, I have to take the output, and then I have to mangle it back into whatever the output of F is supposed to be. Like, all of that stuff should be a lot easier if FHE just works. And I think that to me, that’s sort of like a mega application. But it makes it much easier development wise.
Guy Itzhaki:
I think people that have heard me speak in the past, I like to give the example of a limited access hackathon that we’ve done in July, together with Zama. And that was really, in the early days, a definite that we had. And I think we were really overwhelmed with developers ability to achieve their goals in, I would say probably less than 24 hours, we had a team to try to build private voting. And they’ve tried doing that using ZK for several months. And in less than 24 hours, they were actually able to achieve 80% of their goals. And the reason for that is just FHE is the right tool for the job. It’s very easy to use. In terms of the actual development, you’re using solidity, as well as an FHE library that enables you to just decrypt and encrypt the data that you want to encrypt and decrypt. And that’s pretty much it. So of course, there are design considerations that need to be taken into account. But actually, it’s very user friendly. The developers don’t really need to understand FHE in order to use it.
Kyle Samani:
All right. Next up, we are gonna get into, I guess a kind of a community question here and maybe Tarun you take this one. Since we can’t eliminate MEV on Ethereum, I was wondering if we can create an application that’s going to be similar to Flashbots that could run on Ethereum, I’m using FHE to minimize MEV?
Tarun Chitra:
Yeah, I mean, if you look at the roadmap, Suave is something that right now is planning on using STX for giving partial privacy to users. So users can encrypt their set of transactions and then reveal some metadata about it, say, “This transaction has a trade whose price needs to be at least X,” but doesn’t tell you exactly the quantity or it doesn’t tell you exactly the price. And then it runs an enclave that is used to determine how to sequence the block and how to charge for it. But I think the and, if you talk to Flash about themselves, I think they also agree that like in a world where FHE is efficient, and a world where they could do it fast enough. They would rather use that than STX. I think it’s really a question of, how do we get to the point that FHE latency wise is competitive with things like the [Unclear 01:01:32], and I think by trying to actually build real applications, like rollups trying to build real applications, like DeFi protocols that are able to give you better guarantees on how interest rates are calculated without revealing a lot about, say, the interest rates that are revealing a lot about the users who are have loans out? I think there’s a lot of stuff in that part of the world that will naturally lead to people figuring out how to make these optimizations, to make things more MEV resistant at the application level. And then as FHE, the latency for execution goes down, being able to use it in more real time systems.
Kyle Samani:
All right. Ah, got it. I guess I think there are just all community questions from here on out. We’ve already kind of touched on this one, but maybe it should recap. What are the biggest differences between ZK and FHE rollups?
Guy Itzhaki:
I can take this one. I think even though it sounds like we’re using the same term. It’s actually not though. The FHE rollups that were discussed in the white paper are really based on using optimistic rollup while introducing data confidentiality through FHE. ZK rollups, they’re mostly for scalability. So I would say, there’s not really a comparison here. And it’s not as if we’ve created the third type of rollup, which is now FHE rollups. But rather, we can say that we’ve taken the optimistic rollups and now for the first time introduced data confidentiality, we’re definitely planning to do the same with ZK once this becomes available, but this is more of a matter of a couple of years, down the line.
Kyle Samani:
All right, and then we are going to keep rolling with these community questions. FHE is advanced, but requires a lot of computation. How can Fhenix offer relative performance? What is the block time?
Guy Zyskind:
Yeah, I’ll take this. I mean, just in general, I’d say that, a big part of why we’re doing like FHE rollups and not like FHE, a side chain over the one is because, like, we feel though, we can scale it much better and much faster using the rollup architecture, that’s obviously true for non-FHE and true for FHE. We’ll still like optimizing and doing a lot of stuff. So I expect people will see things get much better and much faster all the time, the next like one to three years. Right now for the first version, again, it depends on transactions. It depends on stuff, but like we’re trying to aim at something like, comparable to Ethereum level on the layer-1. So not quite as a non-encrypted rollout phase that’s going to take a bit longer, but like between the Ethereum level scalability, maybe actually even slightly less for the first version. So maybe block times will be like, 30 seconds, instead of 15 seconds, maybe you can feed about like half of the transactions, you would in a blog, or you would feed the same amount of transactions, but the blocks are like two weeks longer, something along those lines.
Guy Itzhaki:
And it’s probably worth mentioning that I think there are over a dozen companies that are actually now either building or looking into building dedicated hardware for homomorphic encryption. And once this comes into the market, which I would say timeline is like 12 to 18 months, this will definitely make a transformation in FHE computation.
Kyle Samani:
Oh, all right. Next up, are there any competitors to Fhenix? And if yes, how is Fhenix different from them?
Guy Itzhaki:
Yeah, I have to take this one. I think the right term to look at the landscape in general is not so much in terms of competition, but rather, I’d say maybe even coalition. And the reason is that, no, there’s a lot of market education that needs to happen. Now. I think we all need to make sure that people understand the value of data confidentiality, the value of FHE. So from our standpoint, if there are others, and yes, there are a few that we can mention, whether they’re doing a through ZK, or through Trusted Execution Environment or through FHE. That’s really in the benefit of everyone, we believe that this market is going to exponentially grow. And there is going to be a place for multiple entities, we have the ones that are leading the market with the FHE infrastructure. So we’ve mentioned Zama, you know, earlier along the way, and they’re definitely one that are in the most advanced place and providing the FHE core capabilities. Sunscreen is another one that’s out there. But these are, you know, I’d say providing the FHE components needed for the blockchain world in terms of others that are actually building IoT infrastructure. So on the Trusted Execution domain, we have the likes of secret networks that we’ve mentioned, that are offering great capabilities using ties. And then we have ATO and Aztec that are doing the same. Same with zero knowledge. I think our unique value here is twofold. A were the first one to actually do the FHE rollups with a FHE. And second is that I would also add the amount of people that really understand FHE is not very high. And we have a really great team here with tons of experience, and both the developer and the business development part. So I would say to summarize it, yeah, we’re doing the rollups, we’re probably the only ones doing FHE roll up at this point, even though we suspect that there will be others. And that’s pretty much it.
Kyle Samani:
Okay, I know, we’re basically over on time. Got two more questions, guys. Let’s go through this quickly. I want to make sure I answer, are we happy to answer all of the community questions? Next one is FHG seems to deal with tons of data, where’s that data stored?
Guy Zyskind:
All so very quickly, there were the usual suspects that you can do it on day one, you can do it on dedicated, like L twos, like data availability layers. We’re still considering which one to choose, or maybe we allow, like both options. FHE I mean, although FHE, uncompress Kali, is there’s quite a big blow up in terms of storage. I mean, that’s right, there’s a technique called Trans ciphering, which, I believe, will be greatly improved, like in the next like, year or so. And trans ciphering is, you know, in very simple terms, a way to compress the cipher text. And you can do that before you store and then you can decompress after you load them. So, generally speaking, the overhead might not actually be as big as is, people might think. But it’s a tradeoff. And, that’s something that we’re kind of gonna have to play with and experiment with. And also see like, you know, what people feel comfortable with in terms of like, cost of storage and all that.
Kyle Samani:
Okay, and the last question here, guys, what does it gonna take to implement Fhenix on top of Ethereum? Is that possible, or does Fhenix only work on its own blockchain?
Guy Zyskind:
Yeah, that’s literally the white paper. The white paper is a car that proves that like, you know, you can build it on top of your favorite, and we’re doing it right now.
Kyle Samani:
Awesome. Well, hey, everyone, I know we ran a few minutes over. Thank you all for tuning in this morning or afternoon or maybe middle of the night, depending on where you maybe appreciate all of the community questions coming in and all of the excitement around Fhenix. I’m very honored to be an investor along with some of the other folks here. And thank you, Guy and guy and team for committing your life to building Fhenix.